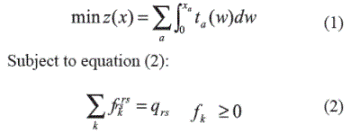안녕하세요 루트에리노입니다.
저번에 교통공학이 어떤건지에 대해 개략적으로 적어봤는데요, 말씀드렸다시피 교통공학이라는게 워낙 넓은 분야이다 보니 제가 어디까지 다룰 수 있을지 아직 감이 잘 잡히지 않습니다.
무슨 교과서들처럼 체계적으로 하기엔 무리도 있고 쓰기에 재미도 없으니, 그때그때 주제를 잡아서 하나씩 말씀드리는 쪽이 좋겠네요.오늘은 교통공학에서 가장 사회적 주목도가 높으면서, 욕도 많이 먹는(...) 수요 예측에 대해 말씀드리고자 합니다. 그중에서도 수요예측에 있어 가장 널리 사용되면서, 현재 예비타당성 또는 투자평가에 사용되고 있는 "4단계 수요예측 기법"을 위주로 말씀드릴게요.
교통장이들의 밥줄 중의 하나인 수요예측은 말 그대로 어떤 노선의 통과교통량이 얼마나 될지 예측하는 방법입니다. 가장 많이 쓰이는 경우는 새로운 노선이 생겼을 경우에 이 노선에 차 또는 사람이 얼마나 지나가게 될 것인지를 예측하는 경우입니다. 꼭 새로운 노선이 아니라도 현재 노선의 유지관리 또는 확장을 위해 수요예측을 실시하는 경우도 있죠.
이 수요예측을 위한 방법 중 가장 단순한 방법은 추세연장법입니다. 여러분도 많이 아실 회귀분석 등의 모형을 통해 미래의 교통량을 맞추려고 하는 방법이죠.
예를들어 A라는 도로에 작년엔 하루에 차가 평균적으로 1,000대쯤 갔고, 올해에 2,000대쯤 갔으니 내년엔 3,000대쯤, 후년엔 4,000대쯤 가겠구나! 하는 게 바로 이 추세연장법입니다. 참 쉽죠? 네, 여러분도 한번 해보세요! 하지만 이 추세연장법에는 큰 맹점이 있습니다.
첫번쨰로 이 추세식이 틀렸을 경우죠. 예를들어 이게 정말 미쳐날뛰는 도로라 알고보니 1년에 두배씩 늘고 있던거라면? 내년엔 4,000대쯤, 후년엔 8,000대쯤 갈 수도 있는거죠. 물론 이런 미친 도로는 세상에 없습니다만. 두번째 맹점은 교통량은 그 자체가 아닌 "다른 경제활동"으로 인한 파생 지표라는 점입니다. 차 타려고 차 타는 경우는 정말 희귀하죠. 보통 교통은 다른 무언가를 하려고 하는 행위니까요. 그래서 교통량 만으로 교통량을 예측하긴 쉽지 않습니다. 따라서 이 방법은 현재 거의 쓰이지 않습니다. 학부생 여러분들의 레포트에는 많이 쓰입니다만 크크. 다만 새 시설이 생기는 경우가 드물면서, 비교적 미시적 지표의 영향력이 미미하다고 볼 수 있는 항공수요에 대해선 시계열 분석 방식을 사용하는 경우가 있습니다.
이러한 맹점을 약간 개선한 것이 수요 탄력성 방식입니다. 예를들어 A라는 지역에 버스정류장을 만들었더니 여기에 교통량이 10% 늘었네! 그러니 B에도 버스정류장을 만들면 10% 늘거야, 라든가...이 방식의 맹점은 변수통제가 힘들고 사례가 없을 경우 대조가 불가능하다는 점이 있습니다. 예를들어 A에 이제 버스정류장 말고 지하철을 깔거야. 그럼 어? 라든가, 그 교통량 10% 늘었어가 강남역에서 잰건데 이제 이걸 울릉도에 적용하면...? 같은 문제점이 발생하는거죠.
이러한 문제점을 해결하기 위해 나온 것이 "순차적 교통수요 모형"입니다. 이중에 현재 가장 널리 사용되는, 사실상 필드에서 대부분의 경우에 사용되는 방식이 4단계 수요모형이죠.
4단계 수요모형은 다음과 같은 코스로 이루어집니다. 예를들어 제가 지금 월급루팡하고 있는 연구실에서 퇴근을 한다고 생각을 하겠습니다.
퇴근하고십따! - 1단계 : 통행발생
집에가야지! - 2단계 : 통행배분
오늘은 월급루팡했으니 기분좋게 택시타야지 - 3단계 : 수단선택
아저씨 앞 큰길은 길이 막히니까 저기 골목길로 돌아가 주세요. - 4단계 : 통행배정
이렇게 4단계로 이루어져 있습니다. 이 4단계들에 대해 하나하나 설명을 드리려면 글을 4개쯤은 써야할테니, 가볍게 설명드리도록 노력하겠습니다.
- 1단계 : 통행발생
통행발생은 어떠한 지역, 저희 교통계에서 존(Zone)이라고 하는 구역에서 몇 명의 사람이 드나드는지를 예측하는 단계입니다. 여기서 나가는 사람을 O(Origin)통행, 들어오는 사람은 D(Destination)통행이라고 합니다. 예를들어 전교생이 700명에 교원 50명짜리 학교가 있다면, 이 학교는 오전에 750명의 D통행을 받고, 오후에 750의 O통행을 발생시키겠죠. 이렇게 각 존의 드나드는 사람 수를 예측하는 단계입니다. 쉽게 말하자면, 하루 평균 얼마나 많은 사람들이 집에서 나왔다 들어가는가, 이것을 예측하는 단계죠.
일반적으로 한 존의 하루단위 O량과 D량은 일치합니다. 사람들의 일반적 통행은 아침에 집에서 나가서 저녁에는 들어오거든요. 원래대로면 밤엔 모두 집에 있어야 하잖아요. 그게 당연하니까요. 근데 왜 눈물이...
해당 통행발생 수를 예측하는데는 인구 수, 사회경제지표 등을 통해 예측합니다. 경제활동인구, 통학인구, 쇼핑통행인구 등이 통행발생수가 되니까요.
와우 호드로 예를 들어볼까요. 이를테면 오그리마는 전통적 베드타운이니 하루에 275명 정도의 왕복 통행이 발생하고, 달라란은 지금 확팩의 중심도시이니 300, 스톰윈드로 수장팟 도는 125명 정도의 통행이 발생한다고 생각해 보겠습니다. 그럼 이 세계의 총 통행량은 800명, 왕복으로 1600통행 정도가 되겠군요.
- 2단계 : 통행배분
이제 아까 집에서 나왔던 사람들이 어디로 들어가는지를 알아보는 단계입니다.
아까 오그리마에서 발생된 275명의 통행에 대해 얘기해 볼까요? 어떤 사람은 오그리마 안에서 팬티입고 춤추고 있을 것이고, 어떤 사람은 퀘하러 힙플레이스 달라란에 갔다 오고 어떤 사람은 수장팟하러 스톰윈드에 가겠죠. 팬티맨 50명, 퀘질 150명, 수장팟하는 고인물 75명이라고 해보겠습니다. 이렇게 되면 오그리마에서 오그리마로 50명, 오그리마에서 달라란에 150명, 오그리마에서 스톰윈드에 75명이 각각 배분됩니다.
아까 말씀드렸다시피 하루 단위 O/D량은 보통 일치하는게 정상이므로, 이렇게 되면 달라란에서도 150명, 스톰윈드에서도 각 75명이 오그리마에 배분되어야 하겠죠? 이것을 어떠한 기준에 따라 각각 맞춰주는 것이 통행배분 과정입니다. 예시로 아래 표와 같이요.
호드 | 도착 (Destination) |
출발 (Origin) | | 오그리마 | 스톰윈드 | 달라란 | 합계 |
오그리마 | 50 | 75 | 150 | 275 |
스톰윈드 | 75 | 0 | 50 | 125 |
달라란 | 150 | 50 | 50 | 300 |
합계 | 275 | 125 | 300 | 700 |
위의 표와 같이, 하루 단위로 각 도시에 출입하는 사람들을 분배할 수 있게 됩니다. 이렇게 발생된 O/D값을 각 존으로 분배시켜 하나의 O/D테이블을 만드는 작업이 통행배분 단계입니다.
주로 사용되는 방법으로는 성장률법, 중력모형의 두가지 방법이 있습니다. 성장률법은 각 존간의 통행량에 대한 자료가 이미 있을 때, 이 통행량의 추세를 이용하는 방법입니다. 중력모형은 각 존간의 통행은 거리에 반비례하고 발생량에 비례한다는 가정을 이용하는 방법이죠.
- 3단계 : 수단선택
수단선택 방식은 말 그대로 교통수단, "뭘 타고 갈래"를 정하는 방식입니다. 생각보다 다루기가 굉장히 까다로운 파트입니다.
여러분이 만약 강남역에서 교대역까지 간다고 가정하겠습니다. 여러분의 선택은 몇가지로 좁혀질 수 있습니다.
1) 지하철 : 통행시간 4분, 접근시간 및 대기시간 7분, 요금 1,250원
2) 버스 : 통행시간 11분, 접근시간 및 대기시간 5분, 요금 1,200원
3) 택시 : 통행시간 11분, 접근시간 및 대기시간 2분, 요금 3,000원
4) 도보 : 통행시간 35분, 접근시간 및 대기시간 없음, 요금 0원, 내가 이러려고 나왔나 자괴감 들어
이런 4가지의 선택이 존재합니다. 하지만 각각의 선호가 모두 다르죠? 그렇기 때문에 이를 확률화하는 모형을 사용합니다. 각 비용 요소마다 가중치를 둬서 실제 몇%가 해당 수단을 선택하는 지를 예측하는 방법이죠. 현재는 대부분 단순하고 정산이 쉬운 로짓(Logit)모형을 이리저리 굴려서 사용하고 있습니다.
- 4단계 : 통행배정
자 이제 여러분은 뭘 탈지도 골랐습니다. 이제 어느 길을 통해 갈지만 고르면 됩니다.
오늘 지하철을 타기로 했는데 왠지 오늘은 환승을 하기가 너무 싫습니다. 그럼 평소 다니던 환승2번하는 노선 말고 시간은 좀 더 걸리지만 한승 1번하는 노선 골라야지! 같은 경우의 수들이 있습니다.
어 근데 아까 3단계에서 이미 통행시간 고려된거 아닌가요? 맞습니다. 그렇기 때문에 통행배정 후에 3단계로 다시 돌아가서 반복적으로 연산을 하는 모형도 있습니다. 다만 현재의 모형 하에서 경로선택에 대한 시간변경은 생각보다 크지 않기 때문에, 생략하는 경우도 있습니다.
통행배정 모형에서는 주로 3가지의 방법을 이용합니다.
1) All-or-Nothing 방식(전량배정법)
이 방법은 가장 쉬운 방법으로서, 그냥 제일 좋은 길에 전부 몰빵해서 간다고 고려하는 방법입니다. 네, 쉽죠? 정말 쉽습니다(...). 근데 이 모형은 여전히 현역입니다. 예를들어 "용량에 따른 제약이 무의미하거나, 용량에 비해 현저하게 작은 교통량만 있을 경우, 또는 교통량의 증가에 따른 비효용 또는 비용이 무시할 수 있을 정도로 적은 경우"에는 실제로 이 방법을 사용합니다. 대부분의 지역간 철도 모형의 경우 여전히, 이 방식을 사용하고 있습니다. 실제로 지역간 철도의 경우 대안이랄게 딱히 존재하지 않는 경우가 많으니까요.
2) 최적 전략 선택 방식
최적전략 방식은 전량배정법에서 좀더 나아간 방법입니다. 가능한 몇개의 전략 중에 제일 나은 애를 고르는 방법이죠. 예를들어 대기시간 5분 남은 최단거리 말고 3분 더걸려도 지금 오는 차를 탄다, 이런 방식이라고 보시면 됩니다. 사실 많은 경우 1)하고 비슷하게 나와요 ㅜㅠ
3) 이용자 평형법(User Equilibrium)
--- 공대생 주의 ---
아래의 내용은 어려울 수 있습니다
위의 2가지 방법은 주로 통행시간에 큰 변수가 없는 통행수단(철도, 항공기)등의 배정에 사용됩니다. 하지만 도로의 경우 교통량에 따른 통행시간의 변수가 미친듯이 큽니다. 그렇기 때문에 위의 두 가지 방법을 사용할 수가 없습니다.
이용자 평형법은 이렇게 교통량에 따라 통행시간 또는 비용이 급변하는 링크를 대상으로 사용하는 방식입니다. 대 원칙은 "이용자 평형이 이루어지면, 어떤 이용자도 더이상 경로변경을 통해 비용을 줄일 수 없다"는 것이죠.
이용자 평형법의 수식은 아래와 같습니다.
교통에 입문하시는 많은 분들이 헷갈려 하시는 것이 위의 (1)번식, 즉 이용자 평형 식이 무언가 나타내는 값이 있다고 생각하시는 건데, 그렇지 않습니다. 해당 수식은 네트워크의 엔트로피를 최대화 하는 교통량을 찾기 위해 설계된 수식입니다. 어떠한 의미있는 물리량을 나타내지 않습니다. (2) 번식은 교통량 제약식입니다.
해당 수식으로 인해 도출되는 이용자 평형 교통량의 특징은, 그 어떤 이용자도 경로 변경을 통해 utility값을 줄일수 없게 된다는 점이 있습니다. 다시 말해, 가능한 어떤 경로를 선택해도 더 나은 경로는 찾을 수 없는 상태를 찾아내는 것이 이용자 평형법이죠. 그리고 실제 도로의 배정이 이렇게 이루어진다고 가정합니다.
이용자 평형법은 어느정도 합리적인 가정에 따른 수식적으로 완성된 수치를 보여주나, 경로분석이 불가능하고, 링크 통행량만을 찾을 수 있고 이용자의 개별특성을 적용하는 것이 불가능하다는 치명적인 단점 역시 존재합니다. 현재 이것을 극복하려는 많은 방식들이 연구중입니다. 특히 확률적 선택을 이용한 SUE모델이 각광받고 있습니다.
----------------------------------
오늘은 교통수요 예측의 이론적인 부분에 대해 써봤습니다. 사실 별로 재미가 없었을지도 모르겠네요 하도 공대같은 내용이라 크크
다음엔 실제 현장에서 교통수요 예측이 어떻게 이루어지고 있는지 신세한탄 겸 해서 말씀드려보도록 하겠습니다!
사실 다 써보려 했는데 이론만 써도 길이 너무 길어져 버렸네요 ㅠㅠ