|
:: 게시판
:: 이전 게시판
|
- 자유 주제로 사용할 수 있는 게시판입니다.
- 토론 게시판의 용도를 겸합니다.
통합규정 1.3 이용안내 인용"Pgr은 '명문화된 삭제규정'이 반드시 필요하지 않은 분을 환영합니다.법 없이도 사는 사람, 남에게 상처를 주지 않으면서 같이 이야기 나눌 수 있는 분이면 좋겠습니다."
21/09/02 10:35
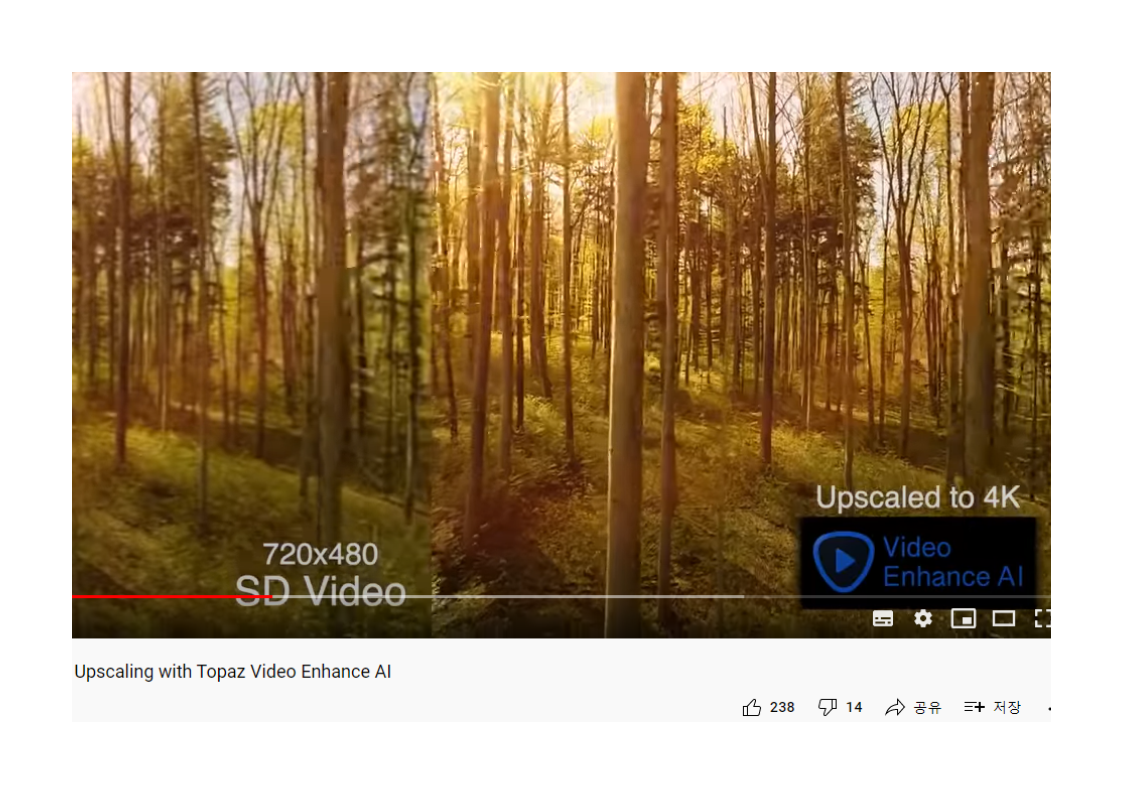
해상도 업스케일링, 프레임 보간 등의 인터폴레이션 기능들은 어쨋든 없는 정보를 추정해서 채워넣는거라 원본에는 없던 패턴 무늬 같은 게 생기는 경우도 있고, 업스케일을 좀 심하게 하면 깨진 그래픽 같이 보이고 하는 현상들이 생기죠... 모자이크 처리를 없애는 것도 상상하시는 경우가 있는데, 모자이크 부분 같은 경우 해상도를 2배 이상 뻥튀기 해야 되는데 이건 거의 새로 그리는 수준이라...
21/09/02 10:40
네 말씀하신대로 후처리기술들은 없는 프레임, 정보들을 만들어 넣는거라 어색한 부분도 있긴합니다.
실시간 처리 기술보다 별도프로그램처리 쪽이 확실히 패턴이나 깨지는 부분들이 적긴 하더라구요. 모자이크는...언젠가 해결되겠죠? 크크
21/09/02 10:38
연구되기로는 엄청난 결과들을 보이고 있는데, 그걸 고해상도 이미지 혹은 비디오에 적용하려면 엄청난 computation이 필요하다는게 문제고..
그래서 TV에서 실시간 upscaling하는 기술은 의외로 굉장히 작은 딥러닝 모델만 들어가거나 그러는 척만 하는 기술이 들어가고 있을겁니다...
21/09/02 10:42
네 재생기기의 실시간 처리기술은 그냥 눈속임에 가까우며(쉴드tv가 그나마 나은 정도..)
프로그램을 통한 영상처리는 엄청난 작업시간이 필요하긴 하죠. 다만 채굴보다 저쪽이 훨씬 생산성 있는 일이 아닐까..생각도 듭니다.
21/09/02 10:54
제가 LG U+ 셋탑박스와 실드TV 프로를 둘 다 쓰는데 동일소스, 동일 재생앱으로 비교해보면 실드TV 프로에 AI업스케일링 모드 적용했을 때 화질이 좀 더 좋긴 하더라고요.
21/09/02 10:55
업스케일 어디까지 되나 한번 480 × 320 영상을 4배 올려봤는데 이미 뭉개진 채로 찍힌 얼굴은 못살리더군요. 휙휙 돌아가는 사진도 좀 뭉개져서 보기 힘들긴 합니다.
이게 그래도 애니메이션에서 훨씬 더 깔끔하게 나오는데 이유를 생각해보니, 애초부터 연속동작이 아닌 프레임단위였고, 그림의 경계 명확하다 보니 더 깔끔하게 처리해주더라구요.
21/09/02 11:02
ai업스케일도 기존의 정보에 추가를 하는거라
기존 영상이 어느정도 받쳐주는 선에서 좋아지기 때문에 720p정도는 되어야 처리된 영상이 볼만하긴 합니다. 애니메이션이야 확실하긴 하죠. 개별 이미지(프레임)들을 처리하기만 해도 되니까요
21/09/02 11:38
이게 좀 궁금한게, AI를 통해 업스케일된 이미지는 실제라고 봐야 할까요?
AI가 자연스럽게 이미지를 보간해 낼 수는 있는데, 실제 이미지와 동일한 이미지를 만들어낼 수는 없지 않을까요? 예를 들어 코 옆에 점이난 어떤 사람의 얼굴을 낮은 해상도(점은 커녕 얼굴도 잘 보이지 않음)에서 AI 업스케일링을 했을때 자연스러운 얼굴로 만들어내겠지만 점을 만들어낸다는건 무에서 유를 만드는 것이니..
21/09/02 13:23
실제하고 차이가있죠. 특히 낮은 해상도는 정보를 덜가지고 있기 때문에 실제와는 차이가 좀 더 납니다.
https://research.nvidia.com/publication/2017-10_Learning-to-Super-Resolve 맨 오른쪽 ground truth가 실제 이미지, 맨 왼쪽 input이 저해상도 이미지, 맨 오른쪽에서 두번째 ours가 복원된 이미지입니다. 요즘 모델이 좀더 자연스러운 이미지가 나오긴할텐데 근본적으로 바뀌는건 없습니다 실제하고는 차이가 생겨요 만약 실제이미지에 점이 있다면 저해상도 이미지에선 점이 있는 픽셀이 조금 어둡게 될텐데 업스케일링 모델이 단순히 피부색을 어둡게할지, 점으로 그려질지, 반점으로 넓게 그릴지, 주름으로 그림자를 만들지는 모르겠습니다.
21/09/02 13:31
명확하게는 원본이란건 존재하지 않습니다.
원본이란게 존재하려면 같은 장면을 같은 조도에서 같은 환경으로 낮은 resolution 카메라로 찍은것을 SR 로 처리 한것과, 같은 장면을 높은 resolution 카메라로 찍은 것과 비교 해야 명확한거죠. 하지만 불가능 하다는것 ... 논문에서도 input을 downsampling 한것을 다시 SR 처리해서 원본과 비교 하고 정량적 수치를 뽑습니다. 원본에 유사하게 가는게 맞아요
21/09/02 13:44
네 그런데 질문자의 질문의도는 그 없는 원본을 가정해서 그것과 얼마나 동일하냐, 얼마나 차이가 생기는지 묻는듯해서요.
유사하지만 차이가 생길수 있다, 저해상도 이미지를 쓸수록 차이가 커지는 경향이 있다로 대답한건데 제 표현이 좋지 않았나봅니다
21/09/02 13:57
답변 감사합니다. 저해상도 일수록 복원이 쉽지 않은건 공감합니다 근데 게시한 영상은 진짜 최악으로 해상도가 안좋은데 저정도로 복원한거도 대단한거 같아요 기술력이 역시 ..
21/09/03 13:48
아니 이런 논의가 있었군요.
제 질문은 저랑 닮은 A, B, C, D 라는 사람이 있고, 실제로 각각의 닮은 사람들은 명확하게 다른 특징들을 가지고 있어서 실제로 보면 "닮았다"이지 다른 사람이라는 것을 알고 있다고 했을 때, 저를 찍은 원본 사진의 이미지가 어느 정도 뭉게 졌을 때 즉 나인지, A, B, C, D 인지 알 수 없는 상태에서 AI를 통해 복원되었을 때 완벽한 C를 생성해 낼 수도 있지 않을까 하는 생각이었어요. 물론 E, F 같은 새로운 중간 점의 이미지가 나올 가능성이 제일 크겠죠. 즉 AI가 자연스럽게 복원한다는 것은 그 간 학습된 데이터에 의한 가장 자연스러운 패턴으로 조합하는 것일텐데, 복원된 이미지와 원래 실존했을 때의 이미지 상의 차이가 크게 의미 있는 산업 (ex 범인 몽타주)에서는 사용했을 때 이 차이를 명확하게 인지하지 않으면 문제가 될 수 있지 않을까? 하는 생각이 들어서였습니다.
21/09/02 14:37
얼마전에 유튭에 추천영상으로 이런게 떠서 봤습니다.
원본영상으로 추측컨데 300이하 해상도에 프레임도 15정도? 될까 보이는데 4k, 60프레임으로 튀겨서 보여주더라구요 [60 fps] Views of Tokyo, Japan, 1913-1915 http://youtu.be/MQAmZ_kR8S8
|
||||||||||||||