|
:: 게시판
:: 이전 게시판
|
- PGR21 관련된 질문 및 건의는 [건의 게시판]을 이용바랍니다.
- (2013년 3월 이전) 오래된 질문글은 [이전 질문 게시판]에 있습니다. 통합 규정을 준수해 주십시오. (2015.12.25.)
통합규정 1.3 이용안내 인용"Pgr은 '명문화된 삭제규정'이 반드시 필요하지 않은 분을 환영합니다.법 없이도 사는 사람, 남에게 상처를 주지 않으면서 같이 이야기 나눌 수 있는 분이면 좋겠습니다."
18/12/23 18:57
import pandas as pd
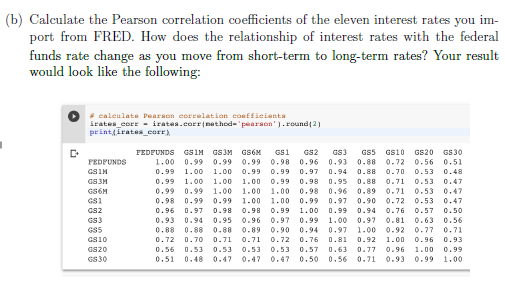
start = date(2007, 1, 1) name_list = [ 'FEDFUNDS', 'GS1M', 'GS3M', 'GS6M', 'GS1', 'GS2', 'GS3', 'GS5', 'GS10', 'GS20', 'GS30' ] data = pd.DataFrame() for name in name_list: _data = DataReader(name, 'fred', start=start)s data[name] = _data[name] print(data.corr()) 이렇게하면 될텐데 몇 가지 확인이 필요할 것 같네요. 1. 각 dataset (_data) 별로 length가 같은지? (len(_data)) - pandas 데이터프레임은 새로운 column을 assign할때 기본적으로 기존 데이터프레임의 index에 맞도록 merge합니다) - 만약 원하는 데이터포맷으로 안붙으면 df1.merge(df2, on=['DATE']) 이런식으로 붙여주시면 될겁니다. 2. 다시 생각해보니 문제될건 위에 하나밖에 없어 보이네요.
18/12/23 19:26
(수정됨) 감사합니다. 데이터는 모두 143 rows라 문제 없을 거 같습니다.
죄송하지만 추가적인 질문이 가능할까요...? 1. 알려주신 코드를 돌려보니 File "<ipython-input-67-88655cbdd3a4>", line 13 _data = DataReader(name, 'fred', start=start)s ^ IndentationError: expected an indented block 가 발생하네요. 이럴 떈 어떻게 고쳐야 할지가 궁금하고 2. 제가 수작업...;으로 FEDFUNDS 부터 GS30까지를 쳤는데, 근본적으로 이 상황에서 행렬같은 dataframe을 만들려면 어떻게 하는지 잘 모르겠네요. 구글링해서 dataframe 을 검색해보면 외부 데이터가 아닌 파이썬 내에서 임의로 만든 행으로만 예시가 되어있어서 ([Korea','Japan','China']나 [1,2,3]같이..) 위와 같이 외부에서 column을 읽어왔을 떄는 dataframe을 어떻게 만드는지 궁금합니다.
18/12/23 19:37
1.
for name in name_list: 아래 두 줄은 tab으로 indentation이 들어가야 합니다. pgr에서 tab이 안먹혀서 저렇게 됐네요ㅠ (for loop 시작하는 줄부터 3줄은 한줄씩 복붙 해주시면 됩니다. ipython이 indent는 알아서 해주니) _data = DataReader(name, 'fred', start=start) data[name] = _data[name] 2. 위의 1 코드가 에러 없이 돌아가면 원하시는 행렬 형태의 데이터프레임이 만들어집니다. pandas dataframe의 column은 기본적으로 series object이고요. data[column_name] = series 이런식으로 기존 dataframe의 column에 새로운 column을 assign할 수 있습니다 (1.의 for loop도 동일한 작업을 한것입니다)
18/12/23 21:00
에러 구문 보고 구글링 후 첫째 줄만 탭해봤는데 안 되길래 이거로는 안되는건가..? 했는데
둘째 줄 까지 해야되는 거였군요. For 반복구문이 뭔지 몰랐는데 그것도 검색해보고 알았습니다 크크ㅠㅠ 설명도 감사하고 결과도 정말 깔끔하게 잘 나오네요. 감사합니다!
|
||||||||||||||