|
:: 게시판
:: 이전 게시판
|
- PGR21 관련된 질문 및 건의는 [건의 게시판]을 이용바랍니다.
- (2013년 3월 이전) 오래된 질문글은 [이전 질문 게시판]에 있습니다. 통합 규정을 준수해 주십시오. (2015.12.25.)
통합규정 1.3 이용안내 인용"Pgr은 '명문화된 삭제규정'이 반드시 필요하지 않은 분을 환영합니다.법 없이도 사는 사람, 남에게 상처를 주지 않으면서 같이 이야기 나눌 수 있는 분이면 좋겠습니다."
14/11/09 00:58
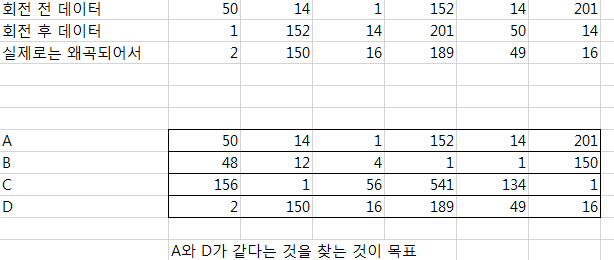
THRESH=2
def data_eq?(p1, p2): for mod_p1 in p1.cyclic_permutations: if sqrt((mod_p1-p2).map{|elem| elem**2}.sum)<THRESH return true return false 대충 pseudocode인데, 이런 식으로 하는 건 어떨까요?
14/11/09 00:59
쉽네요. abcdef를 두번 붙여서 abcdefabcdef로 만들고 그 안에 찾으시는 데이터가 있는지 검색하면 선형시간이네요.
다시 보니까 exact 매치가 아니라 선형은 아니네요. 그래도 뭐 비슷합니다. 픽셀값의 차이를 바탕으로 적절한 거리를 매기면 되겠죠 두번 붙이는 이유는 그렇게 하면 원래 데이터의 모든 rotation들을 substring으로 갖게 되기 때문입니다. 냠.
14/11/09 01:19
matching algorithm을 스마트하게 가져가면 비교회수를 2배보다 더 많이 늘리지 않고 (정확히는 O(N1+N2) 정도에) 해결할 수 있습니다. KMP 알고리즘이나 Suffix array 등의 문자열 처리 알고리즘에 대해 검색해보시면 됩니다.
14/11/09 01:27
데이터가 shift되면서 값이 조금씩 바뀌기 때문에 바뀌기 전이랑 정확하게 1:1매칭이 되는것이 아니라서...
모든 substring들의 유클리드 거리를 서로 비교해보고 가장 작은 값을 찾는 식으로 해야할 것 같습니다. 그래도 써주신 내용은 알고리즘 공부하는데 많은 도움이 될 것 같습니다. 감사합니다!
14/11/09 02:26
그런데 변형이 일어나도 어느정도는 비슷하다는 전제가 있기 때문에, 어떤 픽셀값이 threshold 이상으로 차이가 나면 그 뒤 픽셀들은 비교를 하지 않아도 되겠죠? 탐색시간이 많이 줄어들 것으로 생각합니다.
14/11/09 02:44
그리고 깊게 생각은 안 해봤지만 (x+a)^2=x^2+2ax+a^2이기 때문에 적절한 전처리를 미리 해 둔다면 시간복잡도를 줄일 수도 있지 않을까 싶은데요
그러니까 비교를 시작하는 위치가 한칸씩 뒤로 이동할 때마다 유클리드 거리를 훨씬 빠르게 알아낼 수 있지 않을까 싶어요
14/11/09 03:08
잘 이해가 안 되서 그런데..
x^2과 a^2항은 다음 유클리드 거리 식때도 바뀌지 않으니 중간의 2ax값들만 구하면 된다는 말씀이신가요?
14/11/09 03:14
일단은 그런데.... 딱히 ax항을 빨리 구할 방법은 떠오르질 않네요 a도 x도 같이 바뀌니까... 이건 그냥 sse같은 simd 명령어로 빨리 철리하는 정도에서 만족해야 할 듯해요
14/11/09 03:20
참고하겠습니다!
교수님은 '처리시간이 얼마나 걸리든 정확하게만 찾을 수 있도록 해라, 너희들에게 프로그래밍 실력을 바라는게 아님' 이라고 말하시지만, 우선 처리시간이 느리면 제가 답답하니... 답변 감사합니다.
|
||||||||||||